Les chaînes de caractères (partie 2)
f-strings
Les f-strings (formatted string literals) sont une manière moderne et pratique
de formater des chaînes de caractères en Python. Elles permettent d'incorporer
des expressions à l'intérieur de chaînes en les précédant de la lettre f.
prenom = "Jean"
nom = "Dupont"
nom_complet = f"{prenom} {nom}"
print(nom_complet) # Affiche "Jean Dupont"
Méthode format
Avant l'introduction des f-strings, la méthode format était couramment
utilisée pour formater des chaînes de caractères. Elle permet d'insérer des
valeurs dans une chaîne en utilisant des accolades {} comme espaces réservés.
prenom = "Jean"
nom = "Dupont"
nom_complet = "{} {}".format(prenom, nom)
print(nom_complet) # Affiche "Jean Dupont"
Méthodes de chaînes de caractères
upper()
La méthode upper() renvoie une copie de la chaîne avec tous les caractères en majuscules.
chaine = "bonjour"
chaine_majuscule = chaine.upper()
print(chaine_majuscule) # Affiche "BONJOUR"
lower()
La méthode lower() renvoie une copie de la chaîne avec tous les caractères en minuscules.
chaine = "BONJOUR"
chaine_minuscule = chaine.lower()
print(chaine_minuscule) # Affiche "bonjour"
strip()
La méthode strip() renvoie une copie de la chaîne avec les espaces en début et en fin de chaîne supprimés.
chaine = " bonjour "
chaine_strippee = chaine.strip()
print(chaine_strippee) # Affiche "bonjour"
find()
La méthode find() renvoie l'indice de la première occurrence d'une sous-chaîne dans une chaîne. Si la sous-chaîne n'est pas trouvée, la méthode renvoie -1.
chaine = "bonjour tout le monde"
indice = chaine.find("tout")
print(indice) # Affiche 8
replace()
La méthode replace() renvoie une copie de la chaîne avec toutes les occurrences d'une sous-chaîne remplacées par une autre sous-chaîne.
chaine = "bonjour tout le monde"
chaine_remplacee = chaine.replace("bonjour", "salut")
print(chaine_remplacee) # Affiche "salut tout le monde"
split()
La méthode split() divise la chaîne en une liste de sous-chaînes en utilisant un séparateur spécifié.
chaine = "bonjour tout le monde"
liste_mots = chaine.split(" ")
print(liste_mots) # Affiche ['bonjour', 'tout', 'le', 'monde']
join()
La méthode join() renvoie une chaîne qui est la concaténation des éléments d'une liste, séparés par une chaîne spécifiée.
liste_mots = ['bonjour', 'tout', 'le', 'monde']
chaine = " ".join(liste_mots)
print(chaine) # Affiche "bonjour tout le monde"
count()
La méthode count() renvoie le nombre d'occurrences d'une sous-chaîne dans une chaîne.
chaine = "bonjour tout le monde"
occurrences = chaine.count("o")
print(occurrences) # Affiche 5
Encodage des chaînes de caractères
Un chaîne de caractères est une séquence de caractères. Or, qu'est-ce qu'un
caractère et comment est-il représenté en mémoire ? Le plus simple est d'associer
chaque graphème à un nombre entier. Par exemple, le caractère a pourrait être associé au nombre 1, le caractère b au nombre 2, etc.
On établie ainsi une correspondance entre les caractères et les entiers. Cette correspondance est appelée un encodage. Il existe plusieurs encodages, mais le plus courant est l'encodage ASCII et UTF-8.
Table ASCII
La table ASCII est un encodage de caractères qui associe chaque caractère à un
nombre entier compris entre 0 et 127. Par exemple, le caractère A est
associé au nombre 65, le caractère B au nombre 66, etc. La table ASCII
comprend également des caractères de contrôle, tels que le retour à la ligne
(\n) et la tabulation (\t). Historiquement, la table ASCII a été conçue pour
représenter les caractères de l'alphabet anglais, mais elle est maintenant
utilisée dans de nombreux systèmes informatiques.
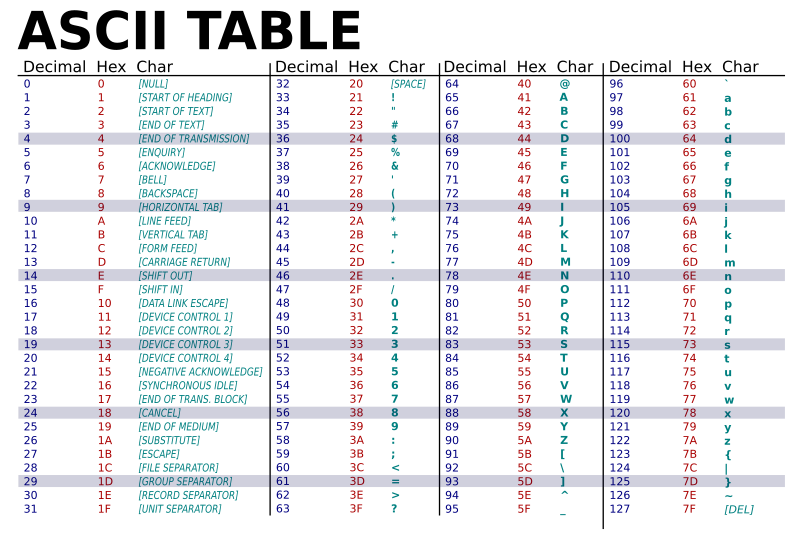
Source : wikimedia
Unicode et UTF-8
Unicode est un standard qui vise à représenter tous les caractères de toutes
les langues du monde. Il associe chaque caractère à un nombre entier unique,
appelé code point. Par exemple, le caractère A est associé au code point
U+0041, le caractère é au code point U+00E9, etc. Unicode comprend également
des caractères spéciaux, tels que les symboles mathématiques et les emojis.
UTF-8 est un encodage de caractères qui permet de représenter tous les caractères Unicode en utilisant un nombre variable d'octets. Les caractères ASCII sont représentés par un seul octet, tandis que les caractères Unicode plus complexes peuvent être représentés par plusieurs octets. Il existe aussi d'autres encodages, tels que UTF-16 et UTF-32, mais UTF-8 est le plus couramment utilisé dans les applications web et les systèmes modernes.
L'important à retenir est unicode est un standard qui vise à représenter tous les caractères de toutes les langues du monde, tandis que UTF-8 est un encodage qui permet de représenter ces caractères en mémoire.
Encodage et décodage en Python
En Python, les chaînes de caractères sont représentées en mémoire sous forme d'objets Unicode. Cela signifie que vous pouvez manipuler des chaînes de caractères sans vous soucier de l'encodage sous-jacent. Cependant, lorsque vous lisez ou écrivez des fichiers, vous devez spécifier l'encodage à utiliser.
Comparaison de chaînes de caractères
La comparaison de chaînes de caractères se fait en utilisant les opérateurs de
comparaison habituels (==, !=, <, >, <=, >=). Les chaînes de
caractères sont comparées lexicographiquement, c'est-à-dire en fonction de
l'ordre des caractères dans la table
Unicode. Notez que la table
ASCII
est un sous-ensemble de la table Unicode.
Voici un exemple d'utilisation des opérateurs de comparaison avec des chaînes de caractères :
str1 = "apple"
str2 = "banana"
print(str1 < str2) # True
print(str1 == str2) # False
print(str1 > str2) # False
str1 = "apple"
str2 = "apple"
print(str1 < str2) # False
print(str1 == str2) # True
print(str1 > str2) # False
str1 = "banana"
str2 = "apple"
print(str1 < str2) # False
print(str1 == str2) # False
print(str1 > str2) # True
En présence de caractères spéciaux, la comparaison de chaînes de caractères
peut donner des résultats inattendus. Par exemple, un même symbole peut être représenté de plusieurs
façon en Unicode. Pour éviter ce genre de problème, il est possible de normaliser les chaînes de caractères
en utilisant la fonction unicodedata.normalize() du module unicodedata.
import unicodedata
# Deux chaînes de caractères qui représentent la même chose
str1 = "école" # Caractère 'é' (U+00E9) + "cole"
str2 = "e\u0301cole" # Caracter 'e' (U+0065) + diacritique accent aigu (U+0301) + "cole"
# Les deux chaînes s'affichent de la même façon
print("Même affichage:")
print(f"str1 (original): {repr(str1)}") # 'école'
print(f"str2 (original): {repr(str2)}") # 'école'
# Mais elles ne sont pas équivalentes sans normalisation
print("Sans normalisation:")
print(len(str1)) # 5
print(len(str2)) # 6
print(f"str1 == str2: {str1 == str2}") # False
# Avec normalisation NFC
str1_nfc = unicodedata.normalize("NFC", str1)
str2_nfc = unicodedata.normalize("NFC", str2)
print("Après normalisation NFC:")
print(f"str1_nfc == str2_nfc: {str1_nfc == str2_nfc}") # True
# Avec normalisation NFD
str1_nfd = unicodedata.normalize("NFD", str1)
str2_nfd = unicodedata.normalize("NFD", str2)
print("Après normalisation NFD:")
print(f"str1_nfd == str2_nfd: {str1_nfd == str2_nfd}") # True